



Serveurs désagrégés : quelles pistes techniques pour améliorer l’efficacité des machines de demain ?
Et si les centres de données fonctionnaient comme un unique super-ordinateur ? Plutôt que d’empiler des serveurs indépendants dans une même armoire, la désagrégation propose de mutualiser les ressources (calcul, stockage, mémoire) pour optimiser leur utilisation. Une approche prometteuse, mais qui soulève des défis techniques majeurs, notamment en matière d’accès aux données et de cohérence des caches. Les projets DiVa et Archi-CESAM explorent des solutions, respectivement côté logiciel et matériel, pour rendre cette vision réaliste.
Des ressources sous-exploitées
Dans les centres de calculs et de données, les serveurs, empilés dans des armoires standardisées (mesurées en “U”, soit 44,45 mm par unité), reproduisent l’architecture d’un ordinateur classique : disques de stockage (SSD/HDD), mémoire vive (RAM), processeurs (CPU) et parfois des accélérateurs spécialisés (cartes graphiques, etc.).
Pourtant, cette réplication systématique est inefficace : les besoins des clients varient. Certains nécessitent beaucoup de RAM (bases de données), d’autres de la puissance de calcul (simulations scientifiques). Résultat : 50 % des machines virtuelles (VMs) n’utilisent que la moitié de leur mémoire allouée, et 25 % de la RAM reste inutilisée quand les ressources CPU sont saturées. (source : https://pages.cs.wisc.edu/~markhill/papers/asplos2023\_pond.pdf )

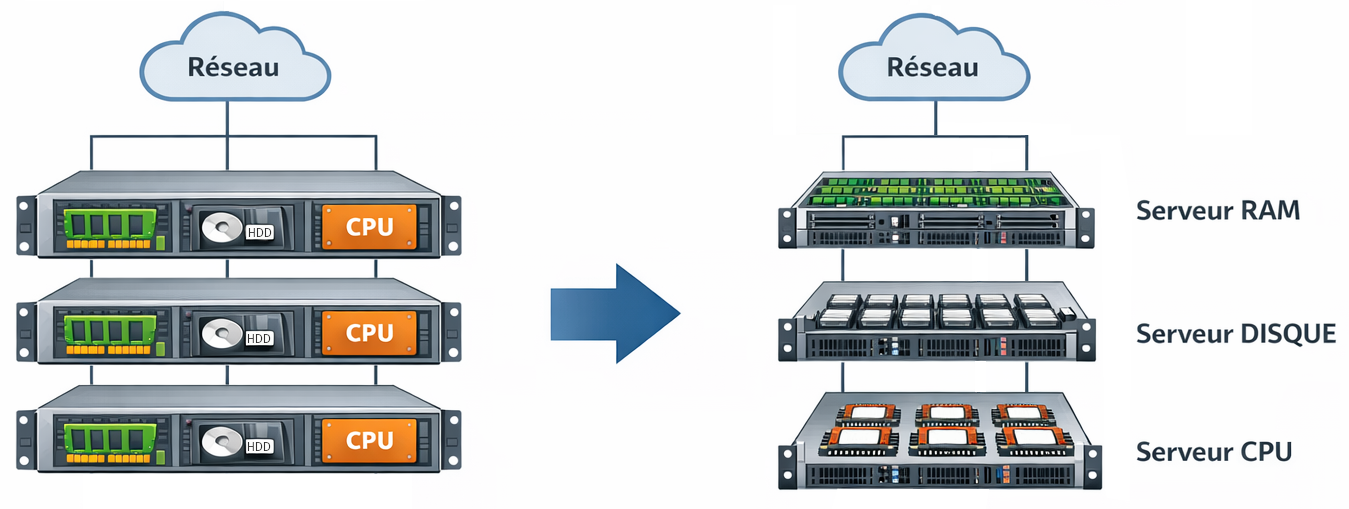
La désagrégation : une réponse à l’inefficacité
Plutôt que de dupliquer des serveurs identiques, la désagrégation spécialise chaque baie :
• une pour la mémoire vive,
• une autre pour le stockage,
• une troisième pour le calcul.
Les ressources deviennent partagées à l’échelle d’un rack, offrant une flexibilité accrue. Par exemple, une machine virtuelle pourrait accéder à une grande quantité de RAM sans être limitée par la capacité d’un serveur unique.
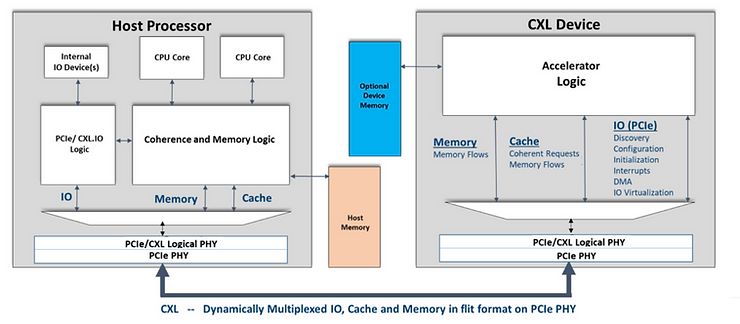
Les défis techniques
1. L’interconnexion des ressources
La mémoire vive doit être accessible ultra-rapidement pour justifier son existence. Or, dans un système désagrégé, les données transitent entre racks mémoires et racks de calcul. Il faut donc :
• Un protocole de cohérence de cache pour garantir l’intégrité des données partagées.
• Une bande passante élevée pour éviter les goulots d’étranglement.
Le protocole CXL (Compute Express Link) répond en partie à ce besoin, mais son industrialisation nécessite un support logiciel adapté.
2. Adapter les algorithmes existants
Les optimisations logicielles des 30 dernières années supposent une mémoire locale ou proche (contrôlée par un CPU voisin). Avec la désagrégation, la mémoire devient distante et plus abondante, mais moins rapide. Deux projets du PEPR Cloud relèvent ce défi :
• DiVa (Disaggregated Virtualisation) : développe de nouvelles primitives de synchronisation et des adaptations du ramasse-miettes (garbage collector) pour les serveurs désagrégés.
• Archi-CESAM : propose des architectures matérielles innovantes, intégrant des unités de traitement directement dans les modules RAM pour y déporter une partie des calculs.
Vers une industrialisation ?
La désagrégation séduit par son potentiel d’optimisation, mais sa mise en œuvre exige de repenser à la fois le matériel et le logiciel. Les avancées en cours, comme CXL ou les travaux du PEPR Cloud, pourraient bien en faire la norme des centres de données de demain.